
 L’outil de visualisation d’occurrences de Google, Google Ngram, a de quoi faire rêver les littéraires comme les curieux du net. La plateforme, qui permet de recenser la fréquence d’apparition de certains termes dans le corpus gigantesque de Google Books, est de plus en plus fréquemment utilisée dans des recherches académiques. À l’occasion, on dissertera du bien-fondé d’appuyer une étude sur un tel outil1, avec les problèmes que posent l’opacité de son fonctionnement ainsi que la nature des données sur lesquelles il travaille, mais il est ici question d’un constat technique plutôt alarmant : alors que de nombreux utilisateurs en tirent des conclusions erronées en ne faisant pas attention aux termes qu’ils entrent dans le champ de recherche (sensible à la casse, espaces, etc…), Google lui-même propose un exemple incohérent.
L’outil de visualisation d’occurrences de Google, Google Ngram, a de quoi faire rêver les littéraires comme les curieux du net. La plateforme, qui permet de recenser la fréquence d’apparition de certains termes dans le corpus gigantesque de Google Books, est de plus en plus fréquemment utilisée dans des recherches académiques. À l’occasion, on dissertera du bien-fondé d’appuyer une étude sur un tel outil1, avec les problèmes que posent l’opacité de son fonctionnement ainsi que la nature des données sur lesquelles il travaille, mais il est ici question d’un constat technique plutôt alarmant : alors que de nombreux utilisateurs en tirent des conclusions erronées en ne faisant pas attention aux termes qu’ils entrent dans le champ de recherche (sensible à la casse, espaces, etc…), Google lui-même propose un exemple incohérent.
Comparer ce qui est comparable
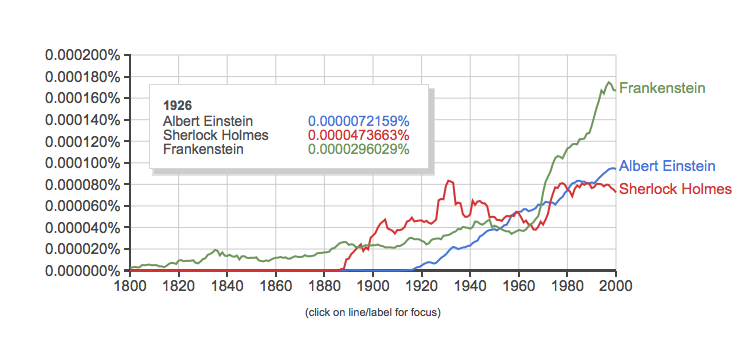
Quand un ami, un collègue ou un conférencier2 s’amuse à comparer les occurrences de “Nixon” avec celles de “Jimmy Carter” et “obama”, on lui fait poliment remarquer que pour la comparaison soit cohérente, il faut comparer “Nixon” avec “Carter” et “Obama” (en enlevant les prénoms et ajoutant la majuscule, ou alors en ajoutant les prénoms de chacun…). Mais sur sa page d’accueil, Google Ngram croit nous surprendre avec la célébrité de Frankenstein, comparée aux citations d’Albert Einstein et de Sherlock Holmes :
Or, la comparaison est biaisée par le fait que Frankenstein n’est pas assorti de son prénom, Victor ! Muni de celui-ci, le résultat est très différent :
On me répondra à raison que, dans la culture populaire, Frankenstein est généralement cité sans son prénom, mais c’est aussi le cas d’Einstein (un peu moins de Holmes ?). Le graphe n’en est pas moins sans appel :
Bref…
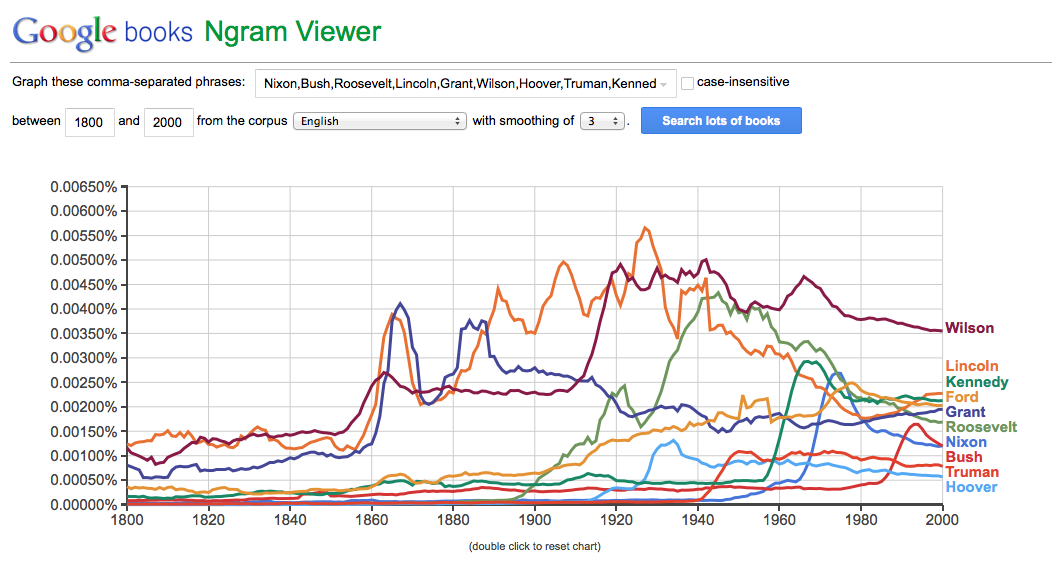
Un exemple de comparaison tout azimut de patronymes de présidents des USA, le genre de graphique totalement aveuglant.
Cet exemple trône sur la page d’accueil de Google Ngram depuis le lancement du service, il ne s’agit donc probablement pas d’une erreur, à moins que le géant de Mountain View n’ait délaissé son joujou depuis. Toujours est-il que cet exemple n’éduque pas l’utilisateur à un usage raisonné de l’outil … et ne facilite pas la tâche des “évangélistes” de la visualisation de données !
Finalement, ces graphes n’ont aucun sens parce que les termes sont susceptibles de référer à des réalités inattendues que seul un examen qualitatif des livres de Google Books pourra rendre intelligible (la fréquence de citations de “Holmes” comme patronyme d’autres personnes que le seul détective d’Arthur Conan Doyle, par exemple). Ah zut, j’avais promis en introduction de n’aborder que la question technique et pas l’interprétation ! 🙂
Un excellent billet. Un autre biais que j’avais cru pouvoir remarquer était que pour les périodiques, c’était en général l’année du lancement de ceux-ci qui était retenu, et non celle du numéro dans lequel le terme apparaissait, ce qui pose également un probléme.
Oh, si c’est le cas, c’est un problème de taille… enfin pour autant qu’on utilise vraiment Google Ngram comme un outil de recherche… (parce que ça ressemble de plus en plus à un outil de communication, au détriment de ses potentialités analytiques).
Merci de cette remarque qui touche à la critique du “fond”, j’en suis resté à la “forme” dans ce billet pour ne pas y passer une semaine 😉
Article qui touche juste. J’ai l’impression qu’un outil qui n’utilise pas les regexp (http://fr.wikipedia.org/wiki/Expression_rationnelle) aura peu de chance de produire son effet. Il faut passer par les recherches avancées (https://books.google.com/ngrams/info#advanced), ce qui rend soudainement la chose beaucoup moins triviale.
Ah oui, les modalités de recherche avancée sont intéressantes. Bon, elles posent de nouvelles questions en matière d’opacité de la machine, par exemple leur outil qui détecte si un mot est un verbe/nom/…