
 La base de données relationnelle est un outil qui accompagne désormais de nombreuses recherches en histoire, un moyen de supporter le chercheur dans l’organisation des nombreuses informations qu’il récolte. Lors du colloque “Digital Humanities” organisé par l’Académie suisse des sciences humaines et sociales pour coordonner les projets suisses en humanités numériques, j’ai présenté un poster qui synthétise en quoi on peut tirer profit d’une telle base de données pour en extraire un réseau de documents d’archives (utile pour la recherche en archives), puis un réseau de personnes (utile pour l’interprétation de ces archives).
La base de données relationnelle est un outil qui accompagne désormais de nombreuses recherches en histoire, un moyen de supporter le chercheur dans l’organisation des nombreuses informations qu’il récolte. Lors du colloque “Digital Humanities” organisé par l’Académie suisse des sciences humaines et sociales pour coordonner les projets suisses en humanités numériques, j’ai présenté un poster qui synthétise en quoi on peut tirer profit d’une telle base de données pour en extraire un réseau de documents d’archives (utile pour la recherche en archives), puis un réseau de personnes (utile pour l’interprétation de ces archives).
Comme plusieurs personnes m’ont suggéré de mettre en ligne ce poster, malgré que son sujet ait déjà été abordé plus longuement dans un récent billet, je mets ci-dessous à disposition le contenu du poster.
Cartographie d’un fonds d’archives
Dans cette situation (ci-dessous), le graphe ne fait que décrire le répertoire d’archives avec ses différents niveaux de classement. De fait, sa structure strictement hiérarchique ne nous renseigne pas sur son contenu mais sur son organisation et le poids des différentes sections ou thématiques à l’intérieur du fonds. Cet aperçu global peut s’avérer pratique pour une première entrée dans l’archive, de même qu’il éclaire la logique d’organisation et de conservation de l’information à l’intérieur de l’institution.
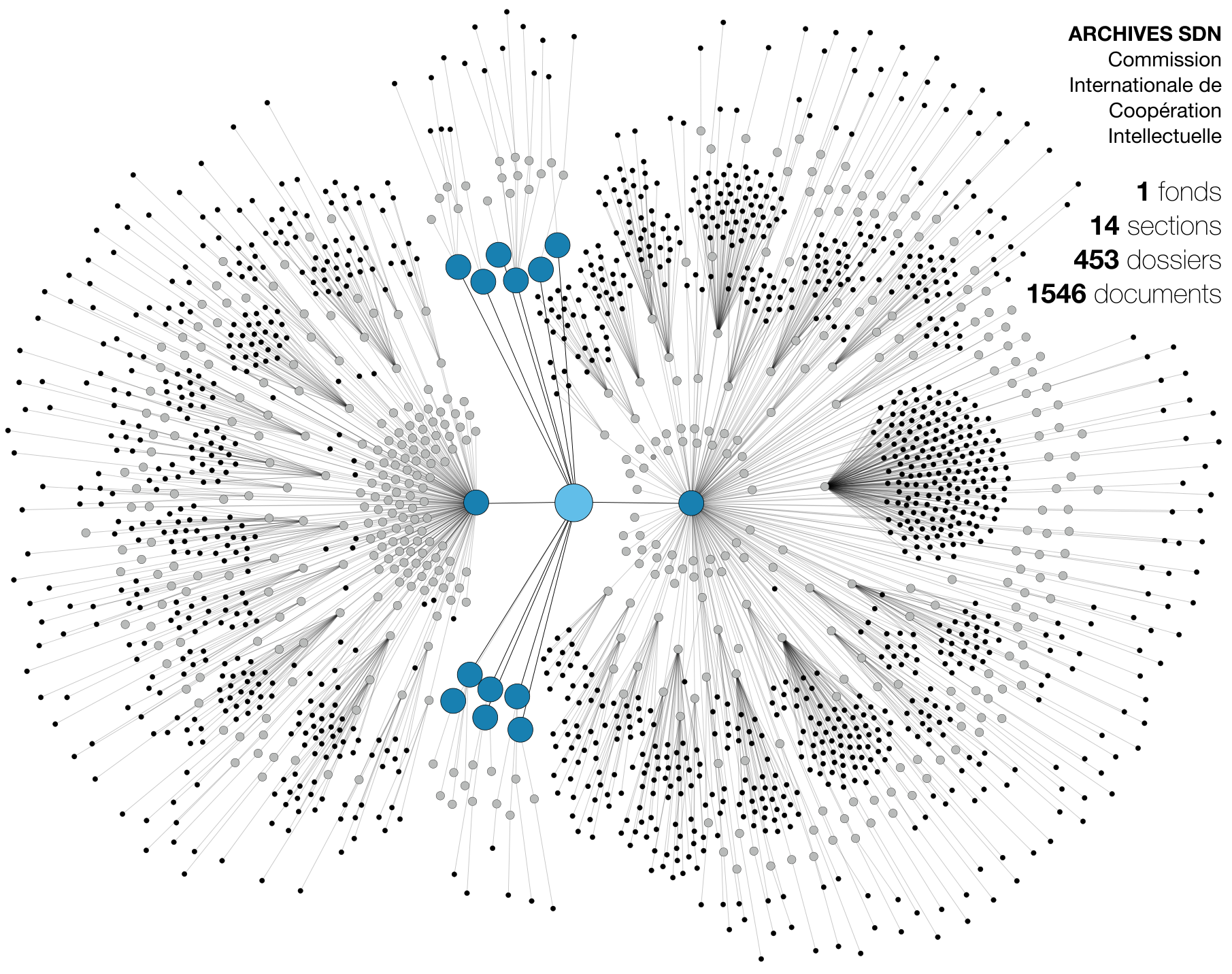
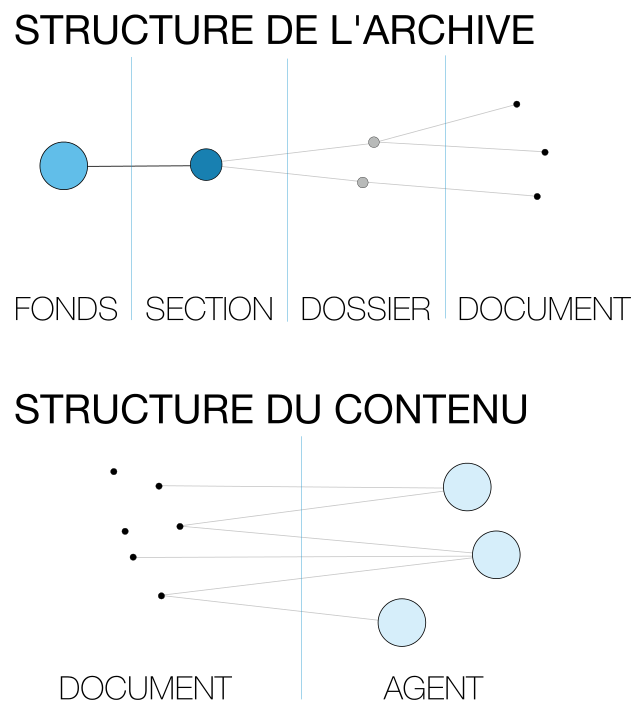 Recenser tous les agents des documents en question (les auteurs, expéditeurs et destinataires) confère à la base de données une nouvelle dimension, à l’image des index de fiches qui existent parfois dans les institutions d’archives et qui permettent de lister tous les documents dans lesquels apparaissent un individu ou une institution.
Recenser tous les agents des documents en question (les auteurs, expéditeurs et destinataires) confère à la base de données une nouvelle dimension, à l’image des index de fiches qui existent parfois dans les institutions d’archives et qui permettent de lister tous les documents dans lesquels apparaissent un individu ou une institution.
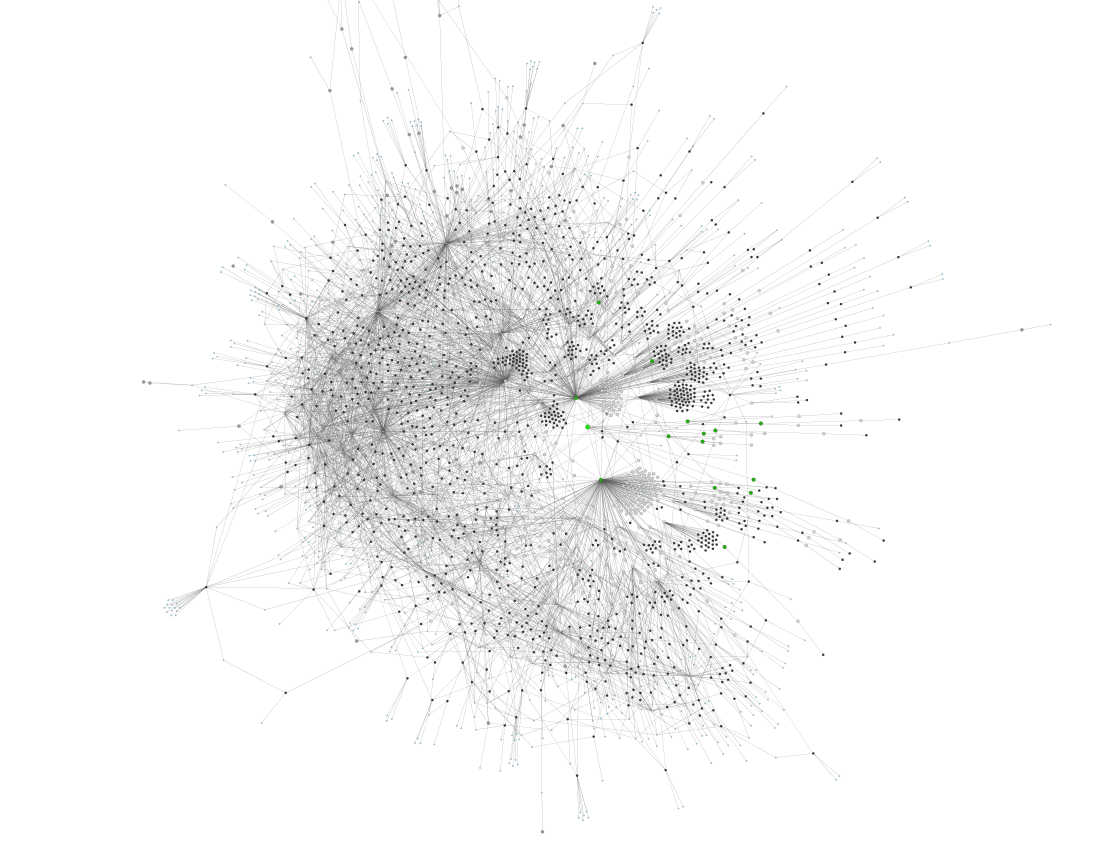
Graphe structurel (et illisible) de l’archive auquel sont ajoutés les 887 agents, reliés aux documents dans lesquels ils apparaissent.
Cet agent, maillon supplémentaire de la chaîne Fonds-Section-Dossier-Document va bouleverser le réseau de l’archive (ci-contre à droite) en lui faisant perdre sa structure hiérarchique. En effet, une personne peut apparaître dans plusieurs documents, eux-mêmes classés dans des sections différentes du fonds. Dès lors, et même si le graphe n’est plus visuellement d’une quelconque aide en raison de sa complexité, cette organisation d’information en réseau va prendre son sens dans une base de données relationnelle (ci-dessous) qui va accélérer le travail de recoupement.
Base de données relationnelle
 Contenant des fiches de plusieurs types, la base de données relationnelle est utilisée comme support à de nombreuses recherches. Son intérêt ne s’arrête toutefois pas à un performant outil de conservation de l’information puisque dans le cas du catalogage d’un fonds d’archives les relations qui s’y tissent peuvent elles-mêmes être analysées : cartographies de correspondances, analyses de réseau de personnes ou organigrammes d’institutions sont rendus possibles.
Contenant des fiches de plusieurs types, la base de données relationnelle est utilisée comme support à de nombreuses recherches. Son intérêt ne s’arrête toutefois pas à un performant outil de conservation de l’information puisque dans le cas du catalogage d’un fonds d’archives les relations qui s’y tissent peuvent elles-mêmes être analysées : cartographies de correspondances, analyses de réseau de personnes ou organigrammes d’institutions sont rendus possibles.
Analyse de réseau : les agents
Quitter le plan de classement pour s’intéresser au contenu des documents est porteur de perspectives tout à fait intéressantes en matière d’analyse de réseau des “agents” des documents en question. On quitte donc la hiérarchie du fonds pour considérer le document comme le témoin d’une relation entre ses agents.
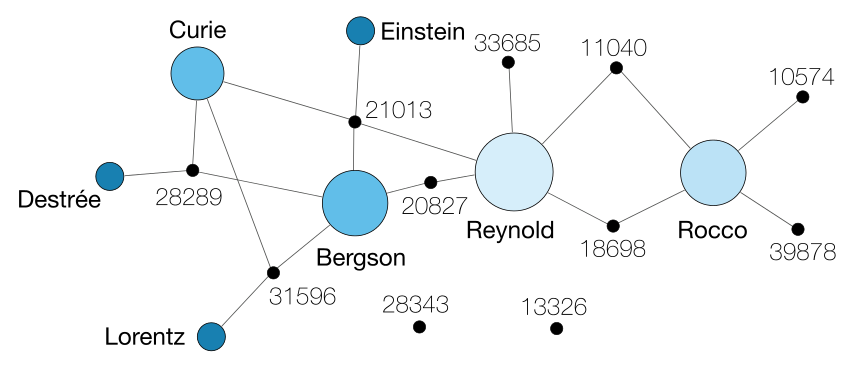 À gauche, un exemple de réseau tiré du dépouillement de quelques dossiers. Chaque document concrétise physiquement le lien entre des membres de la Commission Internationale de Coopération Intellectuelle de la SDN. Un document peut ne contenir aucun “agent” (un rapport non signé, par exemple), un seul (un document signé mais non adressé), deux (une lettre) ou plus (une correpondance co-signée, ou adressée à plusieurs personnes).
À gauche, un exemple de réseau tiré du dépouillement de quelques dossiers. Chaque document concrétise physiquement le lien entre des membres de la Commission Internationale de Coopération Intellectuelle de la SDN. Un document peut ne contenir aucun “agent” (un rapport non signé, par exemple), un seul (un document signé mais non adressé), deux (une lettre) ou plus (une correpondance co-signée, ou adressée à plusieurs personnes).
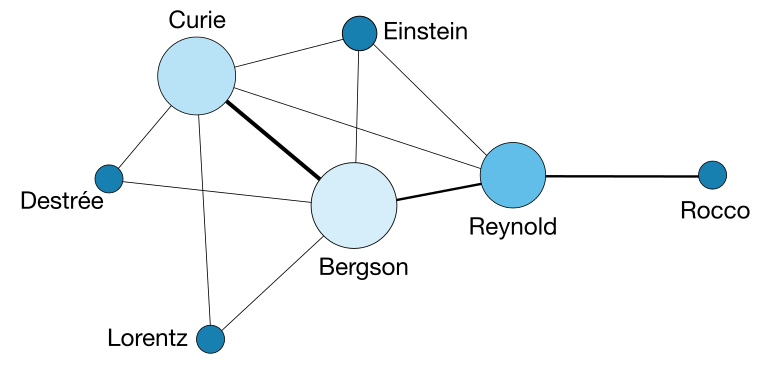 À droite, le même exemple de réseau, après projection. Les documents sont résumés par une arête directe entre leurs agents. Celle-ci peut être plus ou moins épaisse en fonction du nombre de documents dans lesquels les agents apparaissent ensemble. À noter que les documents qui ne contenaient qu’un seul agent disparaissent puisqu’ils ne concrétisent pas une relation (c’est pour cette raison que “Reynold” a une importance moindre dans le graphe projeté que dans le graphe original).
À droite, le même exemple de réseau, après projection. Les documents sont résumés par une arête directe entre leurs agents. Celle-ci peut être plus ou moins épaisse en fonction du nombre de documents dans lesquels les agents apparaissent ensemble. À noter que les documents qui ne contenaient qu’un seul agent disparaissent puisqu’ils ne concrétisent pas une relation (c’est pour cette raison que “Reynold” a une importance moindre dans le graphe projeté que dans le graphe original).
En plus d’une meilleure lisibilité, le passage d’un graphe à deux types de noeuds (documents et agents) vers un graphe à un seul type (agents seuls) permet d’étudier ses propriétés avec les outils des mathématiques (en particulier les mesures de centralisé). Ci-dessous, le graphe complet :
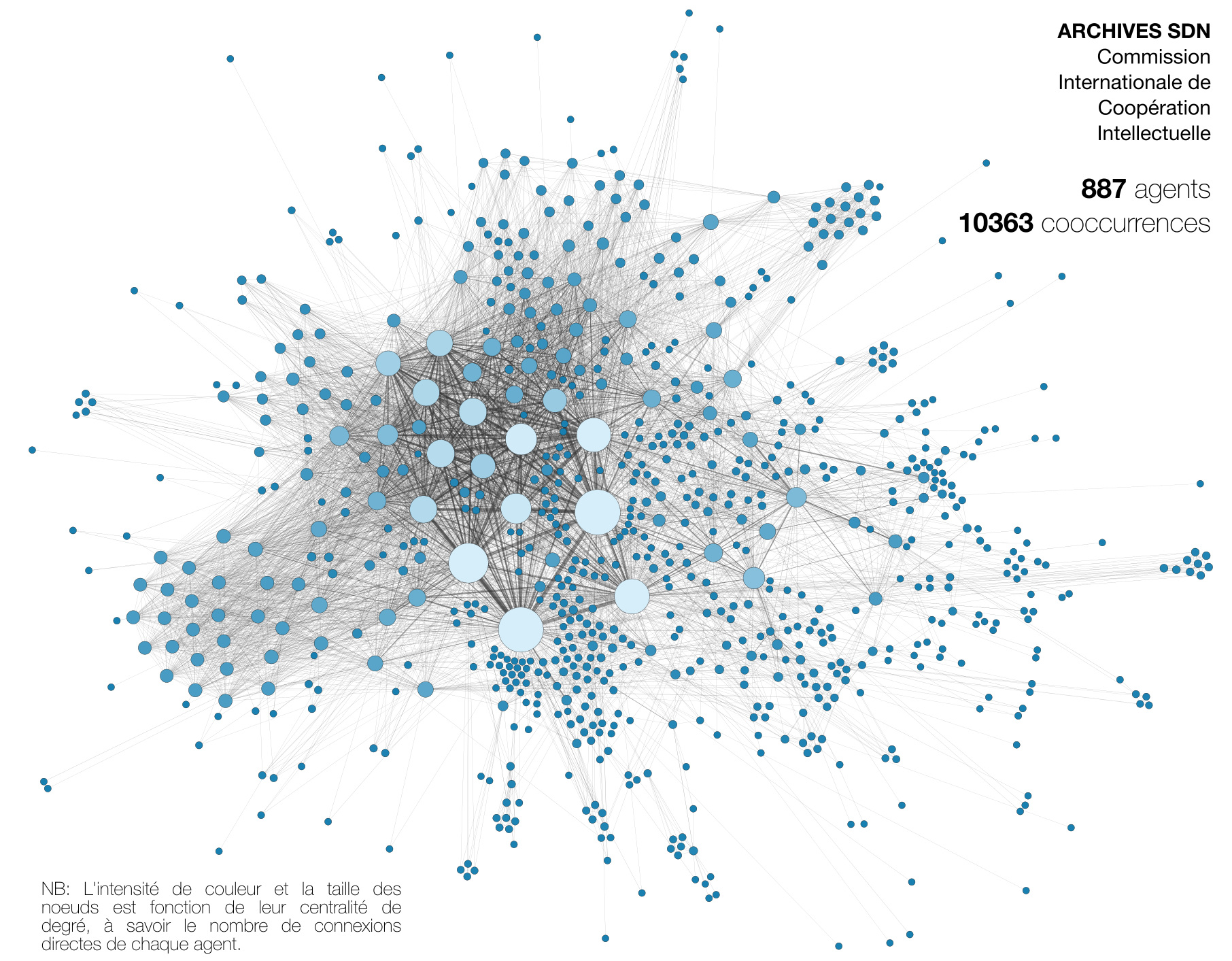
{kind=link}
Toutes les visualisations ont été réalisées avec Gephi.
Est-il possible d’en savoir un peu plus sur la BDD relationnelle? Notamment les outils utilisés (local, serveur, etc.)?
Et surtout, est-il possible de nous donner le structure complète de la base? Ou est-ce un secret? Merci d’avance.
La BDD est construite sur la base de deux fichiers Excel (en fait, sur GoogleDrive parce qu’un collègue travaille sur le même fonds) : l’un contient les informations sur les documents, l’autre sur les personnes, institutions, lieux. Ensuite, ces fichiers sont passés sur FileMaker pour avoir le loisir d’y ajouter des champs de description prospographique, en particulier pour les personnes. En l’état, la base est en local. Mais fondamentalement, les fichiers Excel suffisent largement à en tirer des graphes comme ceux-ci, puisqu’il ne s’agit que de deux listes de “couples” d’Id de personnes et d’Id de documents.